Usage
Airflow can run in standalone mode (see https://airflow.apache.org/docs/apache-airflow/stable/start/local.html) but requires 2 external dependencies if we want to run jobs across more than one worker: these dependencies are
-
an external database (e.g. postgresql) for user/job data, and
-
a queuing component such as Redis.
External dependencies for the Airflow users/job data and job queues
For testing purposes, first add the bitnami repository to helm:
helm repo add bitnami https://charts.bitnami.com/bitnamiYou can spin up a PostgreSQL database with the following command:
helm install airflow-postgresql bitnami/postgresql --version 11.0.0 \
--set auth.username=airflow \
--set auth.password=airflow \
--set auth.database=airflowA Redis instance can be setup in a similar way:
helm install redis bitnami/redis \
--set auth.password=redisSecret with Airflow credentials
A secret with the necessary credentials must be created:
apiVersion: v1
kind: Secret
metadata:
name: simple-airflow-credentials
type: Opaque
stringData:
adminUser.username: airflow
adminUser.firstname: Airflow
adminUser.lastname: Admin
adminUser.email: airflow@airflow.com
adminUser.password: airflow
connections.secretKey: thisISaSECRET_1234
connections.sqlalchemyDatabaseUri: postgresql+psycopg2://airflow:airflow@airflow-postgresql.default.svc.cluster.local/airflow
connections.celeryResultBackend: db+postgresql://airflow:airflow@airflow-postgresql.default.svc.cluster.local/airflow
connections.celeryBrokerUrl: redis://:redis@redis-master:6379/0The connections.secretKey will be used for securely signing the session cookies and can be used
for any other security related needs by extensions. It should be a long random string of bytes.
connections.sqlalchemyDatabaseUri must contain the connection string to the SQL database storing
the Airflow metadata.
connections.celeryResultBackend must contain the connection string to the SQL database storing
the job metadata (in the example above we are using the same postgresql database for both).
connections.celeryBrokerUrl must contain the connection string to the Redis instance used for queuing
the jobs submitted to the airflow worker(s).
The adminUser fields are used by the init command to create an admin user.
Creation of an Airflow Cluster
An Airflow cluster must be created as a custom resource:
apiVersion: airflow.stackable.tech/v1alpha1
kind: AirflowCluster
metadata:
name: airflow
spec:
version: 2.2.4-python3.9-stackable0.3.0
statsdExporterVersion: v0.22.4
executor: CeleryExecutor
loadExamples: true
exposeConfig: false
credentialsSecret: simple-airflow-credentials
webservers:
roleGroups:
default:
replicas: 1
workers:
roleGroups:
default:
replicas: 2
schedulers:
roleGroups:
default:
replicas: 1Please note that the version you need to specify is not only the version of Airflow which you want to roll out, but has to be amended with a Stackable version as shown. This Stackable version is the version of the underlying container image which is used to execute the processes. For a list of available versions please check our image registry. It should generally be safe to simply use the latest image version that is available.
Where:
-
metadata.namecontains the name of the Airflow cluster -
the label of the Docker image provided by Stackable must be set in
spec.version -
spec.statsdExporterVersionmust contain the tag of a statsd-exporter Docker image in the Stackable repository. -
spec.executor: this setting determines how the cluster will run (for more information see https://airflow.apache.org/docs/apache-airflow/stable/executor/index.html#executor-types): theCeleryExecutoris the recommended setting althoughSequentialExecutor(all jobs run in one process in series) andLocalExecutor(whereby all jobs are run on one node, using whatever parallelism is possible) are also supported -
importing the sample workflows is determined by
loadExamples -
exposeConfigallows the contents of the configuration fileairflow.cfgto be exposed via the webserver UI. This is only for debugging purposes and should be set tofalseotherwise as it presents a security risk. -
the previously created secret must be referenced in
credentialsSecret
Each cluster requires 3 components:
-
webservers: this provides the main UI for user-interaction -
workers: the nodes over which the job workload will be distributed by the scheduler -
schedulers: responsible for triggering jobs and persisting their metadata to the backend database
Monitoring
The managed Airflow instances are automatically configured to export Prometheus metrics. See Monitoring for more details.
Configuration & Environment Overrides
The cluster definition also supports overriding configuration properties and environment variables, either per role or per role group, where the more specific override (role group) has precedence over the less specific one (role).
| Overriding certain properties which are set by operator (such as the HTTP port) can interfere with the operator and can lead to problems. Additionally for Airflow it is recommended that each component has the same configuration: not all components use each setting, but some things - such as external end-points - need to be consistent for things to work as expected. |
Configuration Properties
Airflow exposes an environment variable for every configuration setting, a list of which can be found in the Configuration Reference.
Although Kubernetes can override these settings in one of two ways (Configuration overrides, or Environment Variable overrides), the affect is the same and currently only the latter is implemented. This is described in the following section.
Environment Variables
These can be set - or overwritten - at either the role level:
webservers:
envOverrides:
AIRFLOW__WEBSERVER__AUTO_REFRESH_INTERVAL: "8"
roleGroups:
default:
replicas: 1Or per role group:
webservers:
roleGroups:
default:
envOverrides:
AIRFLOW__WEBSERVER__AUTO_REFRESH_INTERVAL: "8"
replicas: 1In both examples above we are replacing the default value of the UI DAG refresh (3s) with 8s. Note that all override property values must be strings.
Initializing the Airflow database
Airflow comes with a default embedded database (intended only for standalone mode): for cluster usage an external database is used such as PostgreSQL, described above. This database must be initialized with an airflow schema and the Admin user defined in the airflow credentials Secret. This is done the first time the cluster is created and can take a few moments.
Using Airflow
When the Airflow cluster is created and the database is initialized, Airflow can be opened in the browser.
The Airflow port which defaults to 8080 can be forwarded to the local host:
kubectl port-forward airflow-webserver-default-0 8080Then it can be opened in the browser with http://localhost:8080.
Enter the admin credentials from the Kubernetes secret:
If the examples were loaded then some dashboards are already available:
Click on an example DAG and then invoke the job: if the scheduler is correctly set up then the job will run and the job tree will update automatically:
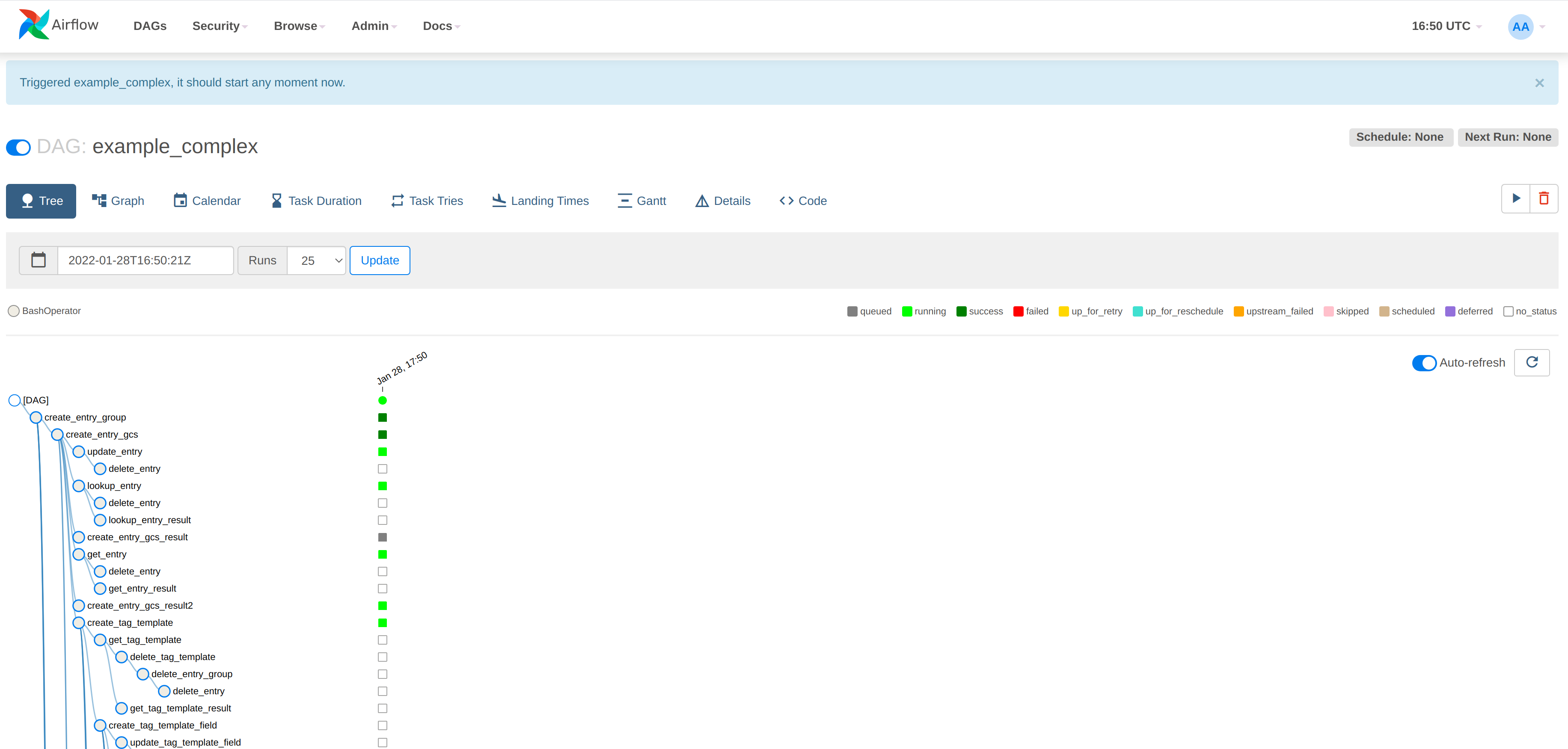
Monitoring
The managed Airflow instances are automatically configured to export Prometheus metrics. See Monitoring for more details
Mounting DAGs
DAGs can be mounted by using a ConfigMap or a PersistentVolumeClaim. This is best illustrated with an example of each, shown in the next section.
via ConfigMap
---
apiVersion: v1
kind: ConfigMap
metadata:
name: cm-dag (1)
data:
test_airflow_dag.py: | (2)
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.dummy import DummyOperator
with DAG(
dag_id='test_airflow_dag',
schedule_interval='0 0 * * *',
start_date=datetime(2021, 1, 1),
catchup=False,
dagrun_timeout=timedelta(minutes=60),
tags=['example', 'example2'],
params={"example_key": "example_value"},
) as dag:
run_this_last = DummyOperator(
task_id='run_this_last',
)
# [START howto_operator_bash]
run_this = BashOperator(
task_id='run_after_loop',
bash_command='echo 1',
)
# [END howto_operator_bash]
run_this >> run_this_last
for i in range(3):
task = BashOperator(
task_id='runme_' + str(i),
bash_command='echo "{{ task_instance_key_str }}" && sleep 1',
)
task >> run_this
# [START howto_operator_bash_template]
also_run_this = BashOperator(
task_id='also_run_this',
bash_command='echo "run_id={{ run_id }} | dag_run={{ dag_run }}"',
)
# [END howto_operator_bash_template]
also_run_this >> run_this_last
# [START howto_operator_bash_skip]
this_will_skip = BashOperator(
task_id='this_will_skip',
bash_command='echo "hello world"; exit 99;',
dag=dag,
)
# [END howto_operator_bash_skip]
this_will_skip >> run_this_last
if __name__ == "__main__":
dag.cli()---
apiVersion: airflow.stackable.tech/v1alpha1
kind: AirflowCluster
metadata:
name: airflow
spec:
version: 2.2.5-python39-stackable0.3.0
statsdExporterVersion: v0.22.4
executor: CeleryExecutor
loadExamples: false
exposeConfig: false
credentialsSecret: simple-airflow-credentials
volumes:
- name: cm-dag (3)
configMap:
name: cm-dag (4)
volumeMounts:
- name: cm-dag (5)
mountPath: /dags/test_airflow_dag.py (6)
subPath: test_airflow_dag.py (7)
webservers:
roleGroups:
default:
envOverrides:
AIRFLOW__CORE__DAGS_FOLDER: "/dags" (8)
replicas: 1
workers:
roleGroups:
default:
envOverrides:
AIRFLOW__CORE__DAGS_FOLDER: "/dags" (8)
replicas: 2
schedulers:
roleGroups:
default:
envOverrides:
AIRFLOW__CORE__DAGS_FOLDER: "/dags" (8)
replicas: 1
| 1 | The name of the configuration map |
| 2 | The name of the DAG (this is a renamed copy of the example_bash_operator.py from the Airflow examples) |
| 3 | The volume backed by the configuration map |
| 4 | The name of the configuration map referenced by the Airflow cluster |
| 5 | The name of the mounted volume |
| 6 | The path of the mounted resource. Note that should map to a single DAG. |
| 7 | The resource has to be defined using subPath: this is to prevent the versioning of configuration map elements which may cause a conflict with how Airflow propagates DAGs between its components. |
| 8 | If the mount path described above is anything other than the standard location (the default is $AIRFLOW_HOME/dags), then the location should be defined using the relevant environment variable. |
The advantage of this approach is that a DAG can be provided "in-line", as it were. This becomes cumbersome when multiple DAGs are to be made available in this way, as each one has to be mapped individually. For multiple DAGs it is probably easier to expose them all via a mounted volume, which is shown below.
via PersistentVolumeclaim
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-airflow (1)
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: batch/v1
kind: Job (2)
metadata:
name: airflow-dags
spec:
template:
spec:
restartPolicy: Never
volumes:
- name: external-dags (3)
persistentVolumeClaim:
claimName: pvc-airflow (4)
initContainers:
- name: dest-dir
image: docker.stackable.tech/stackable/tools:0.2.0-stackable0
env:
- name: DEST_DIR
value: "/stackable/externals"
command:
[
"bash",
"-x",
"-c",
"mkdir -p $DEST_DIR && chown stackable:stackable ${DEST_DIR} && chmod -R a=,u=rwX,g=rwX ${DEST_DIR}",
]
securityContext:
runAsUser: 0
volumeMounts:
- name: external-dags (5)
mountPath: /stackable/externals (6)
containers:
- name: airflow-dags
image: docker.stackable.tech/stackable/tools:0.2.0-stackable0
env:
- name: DEST_DIR
value: "/stackable/externals"
command: (7)
[
"bash",
"-x",
"-c",
"curl -L https://raw.githubusercontent.com/apache/airflow/2.2.5/airflow/example_dags/example_bash_operator.py \
-o ${DEST_DIR}/example_bash_operator.py && \
curl -L https://raw.githubusercontent.com/apache/airflow/2.2.5/airflow/example_dags/example_complex.py \
-o ${DEST_DIR}/example_complex.py && \
curl -L https://raw.githubusercontent.com/apache/airflow/2.2.5/airflow/example_dags/example_branch_datetime_operator.py \
-o ${DEST_DIR}/example_branch_datetime_operator.py",
]
volumeMounts:
- name: external-dags (5)
mountPath: /stackable/externals (6)---
apiVersion: airflow.stackable.tech/v1alpha1
kind: AirflowCluster
metadata:
name: airflow
spec:
version: 2.2.4-python39-stackable0.3.0
statsdExporterVersion: v0.22.4
executor: CeleryExecutor
loadExamples: false
exposeConfig: false
credentialsSecret: simple-airflow-credentials
volumes:
- name: external-dags (8)
persistentVolumeClaim:
claimName: pvc-airflow (9)
volumeMounts:
- name: external-dags (10)
mountPath: /stackable/external-dags (11)
webservers:
roleGroups:
default:
envOverrides:
AIRFLOW__CORE__DAGS_FOLDER: "/stackable/external-dags" (12)
replicas: 1
workers:
roleGroups:
default:
envOverrides:
AIRFLOW__CORE__DAGS_FOLDER: "/stackable/external-dags" (12)
replicas: 2
schedulers:
roleGroups:
default:
envOverrides:
AIRFLOW__CORE__DAGS_FOLDER: "/stackable/external-dags" (12)
replicas: 1| 1 | The name of the PersistentVolumeClaim that references the PV |
| 2 | Job used to populate the PersistentVolumeClaim with DAG files |
| 3 | The volume name that will be mounted as a target for the DAG files |
| 4 | Defines the Volume backed by the PVC, local to the Custom Resource |
| 5 | The VolumeMount used by the Custom Resource |
| 6 | The path for the VolumeMount |
| 7 | The command used to access/download the DAG files to a specified location |
| 8 | The Volume used by this Custom Resource |
| 9 | The PersistentVolumeClaim that backs this Volume |
| 10 | The VolumeMount referencing the Volume in the previous step |
| 11 | The path where this Volume is located for each role (webserver, worker, scheduler) |
| 12 | If the mount path described above is anything other than the standard location (the default is $AIRFLOW_HOME/dags), then the location should be defined using the relevant environment variable. |